6. ファイルの読書き¶
入出力するデータが膨大であれば、ファイルから読んだり書き出したりした方 が便利です。測定したデータは、一般にファイルに保存されるのでpythonでデー タファイルを読んで処理できれば便利です。またプログラムで処理した結果を ファイルに保存できれば、別のソフトウェアで読んで処理することもできます。 第6回では、ファイルからデータを読んだり、ファイルにデータを書き込む(保 存する)方法を学習します。第6回講義の目的は以下のとおりです。
ファイル識別子を使ってファイルのデータを読み書きする方法を学ぶ。
ファイルからデータを読む方法を理解する。
プログラムの処理結果をファイルに書き出す方法を理解する。
ファイルの種類¶
形式 |
中身 |
|---|---|
ascii |
人間の目で確認できる文字列 |
binary |
人間の目で確認できないデータの並び |
ファイルの種類は、大きく分けてasciiをbinaryに2種類です。binary形式の方 がファイルサイズは圧縮できますし、データをそのまま保存できますが、ファ イルの中身を人間の目で見て理解できません。また、ハードウェアの違うコン ピュータでデータを読むために特別な処理が必要になります。巨大なファイル を保存する場合、バイナリ形式を使うこともありますが、ファイルの扱いやす さからasciiファイルの読み書きだけを講義で取扱います。
注釈
ダブルクリックでファイルを開く場合、OS(windows等)が拡張子でソフトウェ アを判断して(docxだとword, xlsxだとexcel等)ファイルを開きます。どのプ ログラムでファイルを開くかの判断は、拡張子をOSが判断してプログラムを 選択しているだけで、ファイルの中身とソフトウェアが関連付けられていな いことに注意してください。
ファイルパス¶
ファイルの置き場所は、パスと呼ばれます。パスの指定方法はいくつかあるの で下にまとめています。
指定方法 |
例 |
|---|---|
絶対パス |
C:/home/hoge/huga/hoge.dat C:からファイルのパスを全て指定する。 |
相対パス |
hoge/hoge.dat (hogeディレクトリの中のhoge.dat) ../hoge.dat (一つ上のディレクトリのhoge.dat)等、相対的にファイルのパスを指定する。 |
ファイル名を指定する場合、 pythonのプログラムが置かれたフォル ダを起点とした相対パスまたは絶対パスでファイル名を指定します。
ファイル記述子¶
ファイルの読み書きは、open() 文でファイル識別子を作成して行います。 ファイルを読み書きするためのモードを指定して、open()文で変数(識別子)を 定義します。open文の書式は以下のとおりです。
file_description = open(filename, mode, encoding="utf8")
読み書きするためのモードは、ファイルを読む書く等でいくつか指定できます。 https://docs.python.jp/3/library/functions.html#open
講義ではよく使う3つのモードだけ紹介します。
モード |
機能 |
|---|---|
"r" |
読み込みモードでファイルを開く。(モードを指定しない場合のdefault) |
"w" |
書き込みモードでファイルを開く。ファイルが存在する場合は、上書きされる。 |
"a" |
追加書き込みモードでファイルを開く。 |
ファイルを読み書きするためのファイル識別子を作成する例です。
1f = open("hoge.txt", "r") # pythonプログラムと同じフォルダにあるhoge.txtを読込みモードで
2f = open("../hoge.txt", "w") # 1つ上のフォルダにあるhoge.txtを書込み読込みモードで
3f = open("huga/hoge.txt", "a") # hugaに入っているhoge.txtを追加書込みモードで
4f = open("Z:/コンピューター処理/day06/test.txt") # ファイルをフルパスで指定, 読み込モード(デフォルト)
日本語等のascii文字以外の文字列を含むファイルを開く場合、endodingを指 定しないとエラーになることがあります。Pythonがファイルを読む時、open文で 指定するエンコード方式と、ファイルの内容のエンコード方式が一致しない場 合、文字化けすることになります。ややこしいですが、歴史的に2つの日本語 のエンコード(文字コード)方式がこれまでに使われてきました。
エンコード |
OS |
|---|---|
SHIFT_JIS または cp932 |
windows |
EUC_JP |
Linux等のUNIX |
日本ローカルなエンコードと異なり、UTF-8は世界中に様々な言語の文字を取 り扱うためのエンコード方式です。UTF-8は世界中のすべての言語を取り扱う ことができるため、今後より普及するかと思います。encodingを指定しない場 合、windows上ではOS標準のcp932でエンコードしたファイルを想定して、ファ イルを読もうします。講義で配布するファイルはUTF-8で統一しています。配 布したファイルを開く場合、encoding="utf8" を指定してください。書 き込みも同様、encodingを指定しない場合は、OS標準のエンコードが適用され ます。また、Excelで読み込ませるcsvファイルは、cp932でエンコードしてお かないと日本語が文字化けしてしまいます。なお日本語を含まないファイルで あれば、特にエンコード方式に気を払う必要はありません。
ファイルの読み込み¶
ファイルを読む手順は、「open()」文で作成した識別子にread()等のメソッ ドを適用して行いますファイルは、読みたい(開きたい)ファイルを"r"モード でopenする必要があります。作成した識別子に「read()」や 「readlines()」メソッドを作用させてデータを読みます。read()と readlines()メソッドの機能は以下のとおりです。
メソッド名 |
機能(戻り値) |
|---|---|
read() |
ファイルの内容が丸ごと入った1つの文字列 |
readlines() |
ファイルの内容の1行が文字列要素となったリスト |
test.txt の内容をプログラムで読んで処理してみます。
test.txt を右クリックして対象を保存するを選択し、pythonプログラムのフォ
ルダと同じ場所に保存します。 test.txt の内容は以下のとおりです。
大学(だいがく、英: college、university)は、学術研究および教育におけ
る高等教育機関である。
x y
1.08330781158 0.883512044446
2.16661562317 0.827688998157
3.24992343475 -0.108119018424
このファイルをread()やreadlines()で読み込んでみます。
1# test.txtをまるごと読み込む
2f = open("test.txt", "r", encoding="utf8") # ファイル識別子fを作成, utf8のエンコード。defaultのcp932だとエラーになる
3data = f.read() # fにread()メソッドを適用してファイルの中身を丸ごとdataにいれる
4print(data) # dataの出力
5
6# test.txtの1行を要素とするリストとして読み込む
7f = open("test.txt", "r", encoding="utf8") # ファイル識別子fを作成
8data = f.readlines() # fにreadlines()を適用して1行毎のリストを生成
9print(len(data)) # dataの要素数=行数を表示
10for l in data: # data を1行ずつ出力
11 print(l)
csvファイルの読み込み¶
Excelで読み書きできるcsvファイルを読んでみます。拡張子がcsvのファイル
はExcelがcsvファイルと解釈してセルにデータを割り当てて読み込んでくれま
す。csvファイルのフォーマットは以下のとおり。1行のデータを列毎に","で
区切ります。csvファイルの例です。 job.csv
category,2010,2011,2012,2013,2014,2015,2016
A,94.40%,91.30%,89.30%,89.20%,90.00%,91.40%,92.80%
B,97.70%,96.70%,90.60%,92.70%,95.10%,95.80%,96.40%
C,98.80%,98.90%,93.60%,89.00%,94.90%,95.00%,95.40%
.
.
.
job.csv を二次元のリストに読み込むプログラムを作成しています。
1lines = open("job.csv", "r").readlines() # 1行毎にリストを作成, 日本語を含まないのでencodeは気にしない
2data = []
3for l in lines:
4 data.append(l.split(",")) # ,でsplit()しながらデータを追加
5for l in data: # 1行毎に出力
6 print(l)
注釈
Excelは、csvファイルを読む際、cp932(shift-jis)でエンコードをされてい ることを想定しているので、pythonでencoding="utf8"で日本語を含むcsvファイルを作成すると 文字化けします。日本語を文字化けせずにexcelに読み込ませるためには、 cp932でエンコードしたファイルを作成する必要があります。
xyzファイルの読み込み¶
分子構造を描画するための原子の種類と原子座標を表現するために、いくかの
ファイルフォーマットが使われています。もっとも単純なファイルフォーマッ
トは、以下のようなxyzファイル(Al2O3.xyz)です。
486
comment
O 3.302190 0.000000 3.248500
O 3.302190 0.000000 16.242500
O 0.921890 4.122801 3.248500
O 0.921890 4.122801 16.242500
.
.
.
496個分のx, y, z座標(angstrom単位)が並ぶ
xyzファイルで作成した分子構造はVESTAで可視化することができます。 VESTAのインストールは次のページを参照してください。(分子構造描画プログラムVESTA)
Al2O3.xyz をプログラムで読んで原子座標の部分を表示させてみます。
1f = open("Al2O3.xyz", "r", encoding="utf8")
2lines = f.readlines() # 1行毎にリストを作成
3atoms = int(lines[0]) # 1行目は原子数
4comment = lines[1] # 2行目はコメント
5symbol, x, y, z = [], [], [], []
6for l in lines[2:]:
7 data = l.split()
8 symbol.append(data[0]) # 原子名
9 x.append(float(data[1])) # x座標
10 y.append(float(data[2])) # y座標
11 z.append(float(data[3])) # z座標
12
13# スペース区切りで出力
14for s, i, j, k in zip(symbol, x, y, z):
15 print("{} {} {} {}".format(s, i, j, k))
ファイルの書き出し¶
ファイルにデータを書き出すためには、「open()」を使って書き込みモード でファイル識別子を作成し、作成した識別子にwrite()メソッドを用います。0 から99までの整数を2乗した数値をoutput.txtに書き込んでみます。
1f = open("output.txt", "w") # 書き込みモードでファイル識別子を作成
2f.write("# test data\n") # 書き込み
3f.write("{:>4s} {:>8s}\n".format("x", "x**2")) # 書き込み
4for i in range(100): # 0から100までの整数
5 f.write("{:4d} {:8.0f}\n".format(i, i**2)) # 2乗した整数をformatで整形して保存
注釈
print()と異なって、write()は自動で改行コードをファイルに書き込みま せん。改行させたい場合は、改行させたいところに改行コード(\n)を指定するようしてく ださい。
もう少し実用的な例として test.txt を読み込んで、ヘッダ(header.txt)とデータ(data.txt)に分離して保存する例です。
1f = open("test.txt", "r", encoding="utf8") # readlines()メソッドで1行ごとのリストを読み込み
2lines = f.readlines() # readlines()メソッドで1行ごとのリストを読み込み
3head = "".join(lines[0:3]) # head部分を結合した文字を生成
4dat = "".join(lines[3:]) # head部分を結合した文字を生成
5h = open("header.txt", "w") # ヘッダー保存用のファイル識別子
6o = open("data.txt", "w") # データ保存用のファイル識別子
7h.write(head) # write()メソッドで書き込み
8o.write(dat) # write()メソッドで書き込み
9print("header.txt was created") # ファイル出力のお知らせ
10print("data.txt was created") # ファイル出力のお知らせ
csvファイルの書き出し¶
Al2O3.xyz のデータを読んで原子座標をcsvファイルで書き出してみます。
1lines = open("Al2O3.xyz", "r").readlines() # 1行毎にリストを作成
2atoms = int(lines[0]) # 1行目は原子数
3comment = lines[1] # 2行目はコメント
4symbol, x, y, z = [], [], [], []
5for l in lines[2:]:
6 data = l.split()
7 symbol.append(data[0]) # 原子名
8 x.append(float(data[1])) # x座標
9 y.append(float(data[2])) # y座標
10 z.append(float(data[3])) # z座標
11
12# スペース区切りで出力
13o = open("Al2O3.csv", "w", encoding="cp932") # 書き込み用の記述子作成, csvはcp932で作成
14for s, i, j, k in zip(symbol, x, y, z):
15 fmt = "{},{},{},{}\n"
16 o.write(fmt.format(s, i, j, k)) # .write()で書き込み
17print("Al2O3.csv was created.") # 書き込み終了の表示
作成したAl2O3.csvをダブルクリックすれば、excelが開いてくれます。
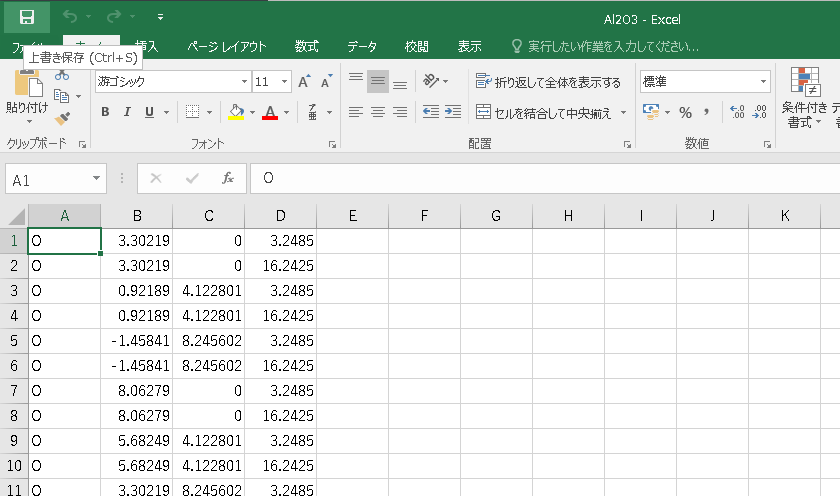
xyzファイルの書き出し¶
四面体構造のCH4(メタン)をプログラムで作成し、xyz形式で出力してみます。C-H結合長さは1.087 Angです。 wikipedia 参照
1outfile = "CH4.xyz" # 出力するファイル名前
2l = 1.0870/(3**0.5/2) # C-H bondlength * 3**0.5/2
3print("C-H bond length: {:.5f} Ang.".format(l * 3**0.5 / 2)) # C-H結合長さの表示
4# 立方体の対角頂点座標からHの座標を作成。立方体の中心はC原子
5data = [["H", 0, 0, 0],
6 ["H", l, l, 0],
7 ["H", l, 0, l],
8 ["H", 0, l, l],
9 ["C", 0.5 * l, 0.5 * l, 0.5 * l]]
10
11o = open(outfile, "w") # 書き込み用記述子の作成
12o.write("{}\n".format(len(data))) # 1行目は原子の数
13o.write("CH4\n") # 2行目はコメント
14for d in data: # 3行目以降、symbol x y zの並びでデータを出力
15 o.write("{:2s} ".format(d[0]))
16 o.write("{:.8f} ".format(d[1]))
17 o.write("{:.8f} ".format(d[2]))
18 o.write("{:.8f} ".format(d[3]))
19 o.write("\n")
20print(outfile, "was created.") # 出力終了のお知らせ
vestaで作成したCH4.xyzを開いて、構造とC-H結合距離を確認してみます。
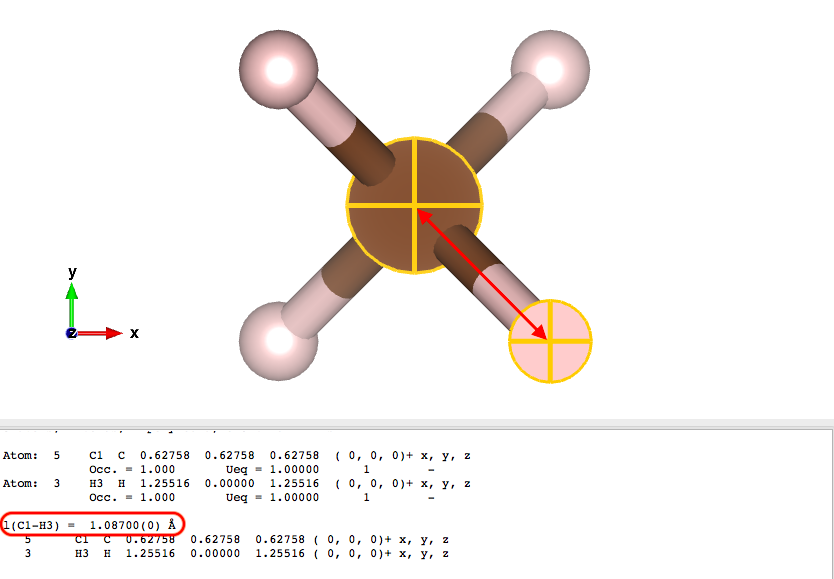
クイズ¶
Q0¶
Toluene.xyzを読んで、2行目以降の元素記号、x, y, z座標を表示する。forで回して出力すること。
答え
# Toluene.xyzをpythonプログラムと同じディレクトリに置いておくこと。
body = open("Toluene.xyz").read()
lines = body.strip().split("\n")
for i, line in enumerate(lines[2:]):
data = line.split()
symbol = data[0]
# ついでに原点からの距離も求めてみる。
r = [float(v) for v in data[1:]]
dist = (r[0]**2 + r[1]**2 + r[2]**2)**0.5
print("{:>2d}:{} ".format(i+1, symbol), end="")
print("({:7.4f}, {:7.4f}, {:7.4f}) r={:.2f}".format(r[0], r[1], r[2], dist))
Q1¶
元素名と原子番号のデータ problem-01.txt
を読んで、 problem-01_align.txt
ような2列の成形したデータを別ファイルとして保存する。1列の文字幅は20と
する。
ヒント
open()で読み込みモード、encoding="utf8"で識別子fを生成してファイルを開く
read()を使ってfから丸ごと文字列データ(body)を読む
bodyをsplit()で分割してリスト(body)を生成
open()で書き込み用に識別子gを生成して、encoding="utf8"でファイルを開く
bodyをenumerate()でforループをつくる。
gへ"{:20s}.format()"を使って要素を書き込み。
要素番号が奇数だったらgへ改行コードを書き込み
答え
outfile = "problem-01_align.txt"
body = open("problem-01.txt", encoding="utf8").read()
body = body.split()
f = open(outfile, "w")
for i, b in enumerate(body):
f.write("{:20s}".format(b))
if i % 2 == 1:
f.write("\n")
print(outfile, "was created.")
Q2¶
県別の平均寿命データ lifetime.txt を読ん
で平均寿命が5番目に長い県を調べる。
ヒント
open()でencoding="utf8"でファイルを開く
readlines()でデータを行毎のリスト(lines)として読む
1と2行目のデータはすてる。lines = lines[2:]
県名(pref)と平均寿命(age)を保存する空のリストを作成
forで回しながら、1行のデータをsplit()する
split()したリストの要素数が2でなければデータを含まないのでスキップ(continue)
sorted()してsortしたage_sortをつくる
age_sortの[-5]が5番目に寿命の長いデータ(age_five)になる。
sortしていないageにindex()を使ってage_fiveの要素番号(idx)を取得する。
idxのprefを表示する。
答え
# データの読み込み
lines = open("lifetime.txt").readlines()
data = []
for l in lines[2:]:
d = l.split()
if len(d) != 2: # 2列のデータでなければデータスキップ
continue
data.append(float(d[1])) # 平均寿命のデータをdataに追加
data_ = sorted(data) # 平均寿命のデータでsort
age_sort = data_[-5] # 5番めの平均寿命を取得
for l in lines[2:]:
d = l.split()
if len(d) != 2: # 2列のデータでなければデータスキップ
continue
if float(d[1]) == age_sort:
print("県名:{}, 平均寿命{}".format(d[0], d[1]))
Q3¶
\(x = 0, 0.1, 0.2, ..., 100\) の数列から以下の式で \(y\) を計算して
xydata.csv と xydata.txt と内容が同じになるようなファイルを生成する。
(\(x\) と \(y\) が列になったデータをファイルに出力し、最終行に \(y\) の平均値を保存する)。列の幅や出力する桁数も同じにすること。生成したcsvファイルはexcelで開いて内容を確認できます。
ヒント
while文でxとyのデータを生成する。(forでも良い。お好みで)
xydata.txtとxydata.csvに書き出すための識別子をopen()文で作成する。 xydata.txtはencoding="utf-8"、xydata.csvはencoding="cp932"とする。
forで回しながら、xydata.txtとxydata.csvにwrite()で1行毎にデータを書き込む
最後に平均値sum(y)/len(y)を出力
答え
1x, y = [], [] # データを保存するリスト
2xi = 0
3while xi <= 100: # yをxから計算しながらyに保存
4 yi = (2*xi**2 + 3*xi)**0.5 + 1/5
5 x.append(xi)
6 y.append(yi)
7 xi = xi + 0.1
8
9output_csv = "xydata.csv" # 出力するファイル名
10output_txt = "xydata.txt" # 出力するファイル名
11f = open(output_csv, "w", encoding="cp932")
12g = open(output_txt, "w", encoding="utf8")
13f.write("{:s},{:s}\n".format("x", "y"))
14g.write("{:>10s} {:>10s}\n".format("x", "y"))
15for xi, yi in zip(x, y):
16 f.write("{:.2f},{:.2f}\n".format(xi, yi))
17 g.write("{:10.2f} {:10.2f}\n".format(xi, yi))
18ave = sum(y)/len(y)
19f.write("{},{:.2f}\n".format("平均値", ave))
20g.write("{} {:.2f}\n".format("平均値", ave))
21print(output_csv, "was created.")
22print(output_txt, "was created.")
Q4¶
example-09を改造してCH4をx方向に5.0 Ang.シフトしたCH4を加えて、2つのCH4構造をもつxyzファイルを作成する。VESTAで構造をみると以下のような構造になります。
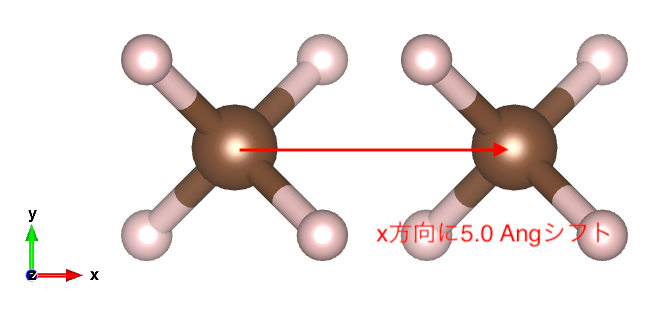
(要注意)data_new = data のようなリスト変数の代入(参照コピー)は使わないこと。関数のところで説明しますがdataのポインタがdata_newにコピーされ要素のコピーは行われません。
ヒント
example-09の要領でCH4の原子座標を定義する。
出力用のファイルをopen()する
2つのCH4分の原子数を1行目に出力
2行めのコメントを出力
シフトしないCH4のデータ(元素記号 x y z)の出力
x方向に5 Ang.シフトしたCH4データ(元素記号 x y z)の出力
答え
1outfile = "CH4-5x.xyz"
2l = 1.0870/(3**0.5/2) # C-H bondlength * 3**0.5/2
3print("C-H bond length: {:.5f} Ang.".format(l * 3**0.5 / 2))
4data = [["H", 0, 0, 0],
5 ["H", l, l, 0],
6 ["H", l, 0, l],
7 ["H", 0, l, l],
8 ["C", 0.5 * l, 0.5 * l, 0.5 * l]]
9
10o = open(outfile, "w")
11o.write("{}\n".format(2 * len(data)))
12o.write("\n")
13for d in data:
14 o.write("{:2s} ".format(d[0]))
15 o.write("{:.8f} ".format(d[1]))
16 o.write("{:.8f} ".format(d[2]))
17 o.write("{:.8f} ".format(d[3]))
18 o.write("\n")
19for d in data:
20 o.write("{:2s} ".format(d[0]))
21 o.write("{:.8f} ".format(2 + d[1]))
22 o.write("{:.8f} ".format(d[2]))
23 o.write("{:.8f} ".format(d[3]))
24 o.write("\n")
25print(outfile, "was created.")
Q5¶
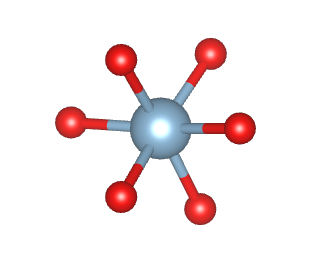
Al2O3.xyz のデータを読んで、
241番のAl原子(x, y, z) = (2.38030, 1.37427, 12.74924)から
2.5 Å以内に存在する原子だけのxyzファイルを作る。vestaで確認すると以下のような構造になります。
ヒント
example-05の要領でxyzファイルの座標データを読み込む
2.5Å以内に存在する原子データを保存するための空リストsymbol_c, x_c, y_c, z_cを定義する。
全原子について、241番目の原子(要素番号240)との距離をforで計算する。 (距離は((x-x0)**2 + (y-y0)**2 + (z-z0)**2)**0.5で計算
forループの中で求めた距離が2.5Å以下ならsymbol_c, x_c, y_c, z_cにデータをappendする。
example-09の要領でsymbol_c, x_c, y_c, z_cをファイルに書き出し。
答え
1# 241番のAl原子(x, y, z) = (2.38030, 1.37427, 12.74924)から
2lines = open("Al2O3.xyz").readlines()
3n = int(lines[0])
4symbol, x, y, z = [], [], [], []
5for l in lines[2:]:
6 data = l.split()
7 symbol.append(data[0].strip())
8 x.append(float(data[1]))
9 y.append(float(data[2]))
10 z.append(float(data[3]))
11
12symbol_c, x_c, y_c, z_c = [], [], [], []
13for i in range(n):
14 dx = (x[240] - x[i])**2
15 dy = (y[240] - y[i])**2
16 dz = (z[240] - z[i])**2
17 r = (dx + dy + dz)**0.5
18 if r < 2.5:
19 symbol_c.append(symbol[i])
20 x_c.append(x[i])
21 y_c.append(y[i])
22 z_c.append(z[i])
23
24# xyzの出力
25outfile = "Al2O3_unit.xyz"
26o = open(outfile, "w")
27o.write("{}\n".format(len(symbol_c)))
28o.write("Al2O6 unit\n")
29for s, xi, yi, zi in zip(symbol_c, x_c, y_c, z_c):
30 o.write("{:3s} {:12.6f} {:12.6f} {:12.6f}\n".format(s, xi, yi, zi))
31print(outfile, "was created")