7. 関数の作成¶
Pythonが標準で準備してくれている標準関数(sorted()等)を取扱いましたが、 関数を自作することも可能です。自作した関数も引数の数と型、返り値を持つ よう作成します。関数を自作するメリットは、繰り返し行う一連の処理まとめ て記述できることです。繰り返し行う処理は、関数としてまとめた方がプログ ラムが読みやすくなりますし、プログラムを修正して管理することも容易にな ります。また、関数内で定義された変数は、関数内だけでしか有効になりませ ん(変数のスコープ)ので、誤って同じ変数を定義してしまうを防ぐことができ ます。標準関数と同様、関数を自作する時は引数の数と型、引数をどのように 設計するかが重要です。第7回講義の目的は以下のとおりです。
引数、返り値を自分で設計して、関数を自作できるようになる。
変数のスコープを理解する。
値の参照渡しを理解する。
関数の定義¶
自作関数の定義は以下のとおりです。 def で関数名を書いて引数として 受け取る変数を()でくくります。関数で行う処理は、インデントをつけて並べ ます。最後に返り値をreturnで並べます。
# 自作関数の定義
def function_name(arg1, arg2...):
関数による処理1
関数による処理2
関数による処理3
.
.
.
return val1, val2
# 自作関数の呼び出し
val1, val2 = function_name(arg1, arg2)
変数を受け取る関数¶
x を受け取って適当な関数を計算する関数を作ってみます。
1# x*x + 3を計算する関数
2def func(k):
3 v = k**2 + 3
4 return v
5
6y = func(3) # 引数x=3で関数の呼び出し
7print("y={}".format(y)) # y=12
関数の中で利用する変数は、関数外で参照することができません。変数の値は 関数内だけでのみ有効です(変数のスコープ)。このような変数のスコープのた め、関数内で使う変数はプログラム内で使っている変数を気にせず好きに使え ることができます。長いプログラムを作成する場合、いつのまにか定義する変 数が被ってしまう場合があります。変数スコープのおかげで関数内で変数名の 被りを気にせずに変数名を使うことができます。関数外で定義されている変数 は グローバル変数 、関数内で定義される変数は ローカル変数 と呼 ばれます。
以下の例では、変数内でzの値を変更していますが、関数外で変数の代入は有 効になっていません(z=3のまま)。
1# x^2 + 3を計算する関数
2def func(k): # kにzの値がコピーされる
3 v = k**2 + 3
4 z = 20 # 関数内でzを定義(代入), 関数内だけの変数スコープ
5 return v
6
7z = 3
8y = func(z) # 引数zで関数の呼び出し
9print("z={}".format(z)) # z=3, 関数内で代入を行っても有効にならない
関数の中で定義されるローカル変数は、 関数の中だけで有効になることに注 意する必要があります。グローバル変数は、関数内で値を参照することができ ますが、内容を変更することができません。どうしても関数内でグローバル変 数を変更したい場合、global文を使って変数を定義する必要があります。
1# x^2 + 3を計算する関数
2def func(k):
3 print(hoge) # グローバル変数の"hoge"が表示される。
4 global z # global変数としてzを定義
5 v = k**2 + 3
6 z = 20 # 関数内でzを定義(代入)
7 return v
8
9hoge = "hoge"
10z = 3
11y = func(3) # 引数x=3で関数の呼び出し
12print("z={}".format(z)) # 関数内でz = 20に更新されている。
関数内でグローバル変数を変更を行うことは、良い作法とされていません。な ぜなら、関数を使うことでグローバル変数にアクセスすることを制限している にもかかわらずglobal文で強引に変更しているからです。global文は、なるべ く使わずに変数の変更が有効となる範囲をなるべく狭く保つことが、読みやす くバグの少ないプログラムにつながります。
可変長引数と複数の返り値の関数¶
標準関数のprint()関数のように、受け取る関数の引数の前に * つけること で可変長の引数を受け取る関数を自作することもできます。関数側で受け取る 変数は、タプル型(要素を変更できないリスト)として受け取ります。
1# 引数として渡した変数の合計に5を足した結果を返す関数
2def func(*l):
3 print(l) # 受け取った可変長引数の表示
4 v = sum(l) + 5 # 合計に5を加えた値を計算
5 return v
6
7print(func(3, 2)) # 10
8print(func(3, 2, 1)) # 11
returnで戻り値も複数して、呼び出し側で受け取ることもできます。
1# 受け取った文字列に-hogeと-hugaを追加した変数を返す関数
2def func(s):
3 s1 = s + "-hoge"
4 s2 = s + "-huga"
5 return s1, s2
6
7s = func("chiba") # 戻り値は[s1, s2]のリストとして受け取り
8print(s)
9a1, a2 = func("chiba") # 戻り値はa1, a2として受け取り
10print(a1, a2)
リストや辞書変数を受け取る関数¶
これまでに紹介した自作関数の例は、引数としてリストや辞書変数を受け取っ ていません。リストや辞書変数を引数として関数に渡す場合、リスト変数の保 存しているメモリーのアドレスがコピーして関数に渡されます。そのため受け 取ったリストや辞書変数の要素を関数内で変更した場合、関数外の実体も変更 されます。以下の例では、引数として渡したリスト変数の要素を変更しています。
1# 要素番号0を10に変更する関数, 返り値はなし
2def func1(l):
3 l[0] = 10 # 関数内でl[0]を10に変更
4
5# 辞書データのkey="hoge"の内容を更新
6def func2(dic):
7 dic['hoge'] = 5
8
9l = [3, 4, 5, 6] # リストの定義
10d = {'hoge': 10, 'huga': 11, 'hege': 12}
11func1(l) # 関数func1()の呼び出し
12func2(d) # 関数func2()の呼び出し
13print(l) # l = [10, 4, 5, 6]
14print(d) # d = {'hoge': 5, 'huga': 11, 'hege': 12}
参照コピーの例を示してみます。
1hoge = [1, 2, 3] # hogeの定義
2huga = hoge # hugaにhogeのアドレスコピー (参照コピー)
3huga[0] = 7 # huga[0]を変更。hoge[0]も変更される。
4print("huga =", huga) # huga = [7, 2, 3]
5print("hoge =", hoge) # hoge = [7, 2, 3]
huga = hoge の代入によって、hogeのアドレスがhugaにコピー(浅いコピー)さ れています。よって、hugaとhogeがデータを保存しているメモリのアドレスは まったく同じです。そのため、hugaの要素を変更するとhogeの要素も変更され ます。一方、以下のように全要素をスライスしてコピー(深いコピー)すれば、 hugaは、hogeと別アドレスになります。
1hoge = [1, 2, 3] # hogeの定義
2huga = hoge[:] # hugaにhogeの要素(アドレスでない)をコピー
3huga[0] = 7 # huga[0]を変更。hoge[0]は変更されない。
4print("huga =", huga) # huga = [7, 2, 3]
5print("hoge =", hoge) # hoge = [1, 2, 3] (最初の定義のまま)
辞書型変数の代入も参照コピー(浅いコピー)になります。参照コピーを避けて 辞書データをコピー(深いコピー)したい場合、copy()メソッドを使います。
1# 辞書変数の浅いコピー(参照コピー)
2huga = hoge # hugaにhogeの要素(アドレスでない)をコピー
3huga[1] = "japan" # huga[1]をjapan変更。hoge[1]も変更される。
4print("huga =", huga) # huga = {1: 'japan', 2: 'b', 3: 'c'}
5print("hoge =", hoge) # hoge = {1: 'japan', 2: 'b', 3: 'c'}
6
7# 辞書変数の深いコピー
8hoge = {1:"a", 2:"b", 3:"c"} # hogeの定義
9huga = hoge.copy() # hugaにhogeのデータコピー(深いコピー)
10huga[1] = "chiba" # huga[1]を変更。hoge[1]は変更されない。
11print("huga =", huga) # huga = {1: 'chiba', 2: 'b', 3: 'c'}
12print("hoge =", hoge) # hoge = {1: 'a', 2: 'b', 3: 'c'}
注釈
C言語等では、データを保存したり文字列を加工するためにポインタ操作を多 用するためポインタの理解は必須になります。露骨なポインタ操作はPython であまりでてこないのですが、リスト変数はデータが保存されているメモリ のアドレスが格納されていることを知っておくと良いかと思います。
注釈
関数内でグローバル変数であるリスト変数の内容を変更する作法は、正しい でしょうか? 変数のスコープを狭めるという観点からは、あまり行儀の良い やり方ではありません。要素をコピーしてデータを関数に渡すことで、グロー バル変数であるリスト変数の内容を保護することができます。ただし、巨大 なリストデータをコピーして関数に渡す場合、余分なメモリを必要とします し、コピーするための処理時間を必要になります。リスト変数をアドレスを 介して参照する場合には、余分なメモリやコピーのための処理時間を必要あ りません。このように一長一短があるのですが、リスト変数のデータ量と保 護(読みやすさ)で使い分ければ良いかと思います。
lambda式による1行関数(無名関数)¶
関数の処理が1行の場合、戻り値のためのreturn文を省略して、引数と処理だ けのlambda式で関数処理を記述できます。以下は、普通に関数を定義した場合 です。
1def func(x, y): # 関数定義
2 z = 3 * x + y + 2 # 1行だけの関数処理
3 return z # 戻り値
4
5
6print(func2(2, 1)) # 関数の呼び出しと出力(9)
同じ処理をlambda式を使って関数処理を1行で書いてみます。
1func2 = lambda x, y : 3 * x + y + 2
2print(func2(2, 1)) # 関数の呼び出しと出力(9)
同じ結果が得られます。
クイズ¶
Q1¶
浮動小数変数を2つ(xとy)を受け取って、3*x+yを返す関数を作成する。
答え
def Func(x, y):
return 3 * x + y
x, y = 5, 4
z = Func(x, y)
print("f({},{}) = {}".format(x, y, z))
Q2¶
2つのリスト変数を受け取って、2つのリストの要素数の総和を返す関数を作 成する。なお、深いコピーで変数を渡す場合と浅いコピーで変数を渡す場合の 2つの呼び出しでプログラムを作成する。
答え
def LenMulti(*lists):
num = 0
for l in lists:
num = num + len(l)
return num
a = [2, 3, 4]
b = [2, 3, 4, 5]
c = [2]
# 浅いコピーでデータを渡す
num = LenMulti(a, b, c)
print("要素数の合計: {}".format(num))
# 深いコピーでデータを渡す
num = LenMulti(a[:], b[:], c[:])
print("要素数の合計: {}".format(num))
Q3 (配布した印刷物と変更しています)¶
前に取り扱った CH4の構造を作成するプログラム を改造して、 下図のように1辺3Åの立方体頂点にCH4を配置する構造のxyzファイルを作成す る。
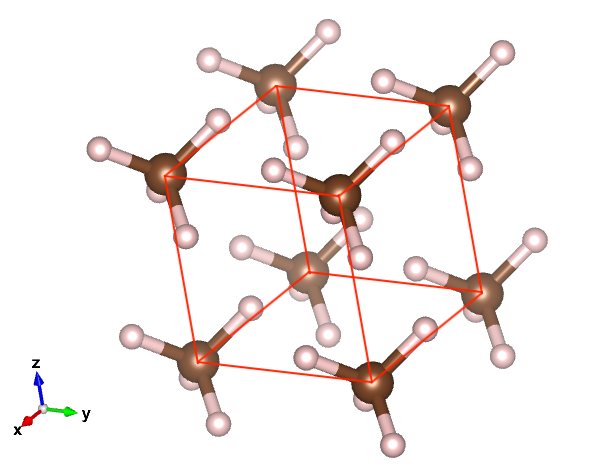
以下のプログラムの関数部分にコードを追加して目的とするプログラムを完成させる。
outfile = "CH4-cubic.xyz"
l = 1.0870 / (3**0.5 / 2) # C-H bondlength * 3**0.5/2
data = [["H", 0, 0, 0],
["H", l, l, 0],
["H", l, 0, l],
["H", 0, l, l],
["C", 0.5 * l, 0.5 * l, 0.5 * l]]
def ShiftData(sx, sy, sz, data):
"""
sx: x方向へのシフト量
sy: y方向へのシフト量
sz: z方向へのシフト量
返り値: dataのx, y, z座標をsx, sy, sz分シフトした新しいdataを
"""
ddata = []
# ここから、 自分で考えてコードを追加する。
# ddataにsx, sy, szずらした原子を追加していく。
# ddataはdataと同じ2次元のデータサイズになります。
for d in data:
print(d)
# ここまで、 自分で考えてコードを追加する。
return ddata
def WriteXYZData(outfile, data):
"""
outfile: 出力するxyzファイル名
data: 出力するデータ
返り値: なし
"""
o = open(outfile, "w")
o.write("{}\n\n".format(len(data)))
for d in data:
o.write("{} {} {} {}\n".format(d[0], d[1], d[2], d[3]))
print(outfile, "was created.")
CH4 = []
# シフトさせたdataをShiftData()で生成しながらCH4を8個追加する。
CH4 = CH4 + ShiftData(0, 0, 0, data)
CH4 = CH4 + ShiftData(3, 0, 0, data)
CH4 = CH4 + ShiftData(0, 3, 0, data)
CH4 = CH4 + ShiftData(0, 0, 3, data)
CH4 = CH4 + ShiftData(3, 3, 0, data)
CH4 = CH4 + ShiftData(0, 3, 3, data)
CH4 = CH4 + ShiftData(3, 0, 3, data)
CH4 = CH4 + ShiftData(3, 3, 3, data)
WriteXYZData(outfile, CH4)
答え
outfile = "CH4-cubic.xyz"
l = 1.0870 / (3**0.5 / 2) # C-H bondlength * 3**0.5/2
data = [["H", 0, 0, 0],
["H", l, l, 0],
["H", l, 0, l],
["H", 0, l, l],
["C", 0.5 * l, 0.5 * l, 0.5 * l]]
def ShiftData(sx, sy, sz, data):
"""
sx: x方向へのシフト量
sy: y方向へのシフト量
sz: z方向へのシフト量
dataのx, y, z座標をsx, sy, sz分シフトした新しいdataをを返す
"""
ddata = []
for d in data:
symbol = d[0]
x = d[1] + sx
y = d[2] + sy
z = d[3] + sz
ddata.append([symbol, x, y, z])
return ddata
def WriteXYZData(outfile, data):
"""
outfile: 出力するxyzファイル名
data: 出力するデータ
返り値なし
"""
o = open(outfile, "w")
o.write("{}\n".format(len(data)))
o.write("\n")
for d in data:
o.write("{:2s} ".format(d[0]))
o.write("{:.8f} ".format(d[1]))
o.write("{:.8f} ".format(d[2]))
o.write("{:.8f} ".format(d[3]))
o.write("\n")
print(outfile, "was created.")
CH4 = []
CH4 = CH4 + ShiftData(0, 0, 0, data)
CH4 = CH4 + ShiftData(3, 0, 0, data)
CH4 = CH4 + ShiftData(0, 3, 0, data)
CH4 = CH4 + ShiftData(0, 0, 3, data)
CH4 = CH4 + ShiftData(3, 3, 0, data)
CH4 = CH4 + ShiftData(0, 3, 3, data)
CH4 = CH4 + ShiftData(3, 0, 3, data)
CH4 = CH4 + ShiftData(3, 3, 3, data)
WriteXYZData(outfile, CH4)
Q4¶
成績データのcsvファイル(score.csv)を読んで「秀」
「優」「良」「可」「不可」にデータを分けて成績順にsortし、「秀」「優」
「良」「可」「不可」で分けたcsvファイルを生成するプログラムを作成する。 score.csv のデータを読んで、以下のようなファイルを出力できれば良い
です。
以下のプログラムの関数部分にコードを追加して目的とするプログラムを完成 させる。
def LoadCsvFile(csvfile):
"""
引数: 読み込むcsvファイル
戻り値: 点数と名前がならんだ2次元のデータ
"""
# Excelは、csvファイルを読む際、cp932(shift-jis)でエンコードを
# されてい ることを想定しているので、pythonでencoding="utf8"で
# 日本語を含むcsvファイルを読み込むと文字化けします。
# 日本語を文字化けせずにexcelに読み込ませるためには、
# cp932でエンコードしたファイルを読みます
o = open(csvfile, "r", encoding='cp932')
lines = o.readlines()[1:]
data = []
for line in lines:
tmp = line.strip().split(',') # 改行コードを削って「,」でsplit()する
data.append([float(tmp[0]), tmp[1]])
return data
def WriteCsvFile(outfile, data):
"""
引数: 保存するcsvファイル
戻り値: 点数と名前がならんだ2次元のデータ
"""
o = open(outfile, "w", encoding="cp932")
o.write("{},{}\n".format("点数", "名前"))
for d in data:
o.write("{},{}\n".format(d[0], d[1]))
print(outfile, "was created.")
def SetDataWrite(smin, smax, data, outfile):
"""
引数: 最小と最大の点数、全データ, 保存するcsvファイル名
戻り値: なし
機能: 点数が最小と最大の範囲にあるデータをdataからスライスしてsort
する。sortしたデータをoutfileにcsv形式で保存する。
"""
sdata = []
WriteCsvFile(outfile, sdata)
data = LoadCsvFile("score.csv")
SetDataWrite(90, 100, data, "秀.csv")
二次元配列を特定の列を基準にsortしたい時¶
sorted()関数にkeyで関数を指定することで、列を基準にしたsortが行えます。 (他のプログラミング言語でも同じような手続きになります。)
# 二次元配列の定義
a = [[1, 2, 5],
[-4, 5, 9],
[3, 8, 3],
[2, 3, 1]]
def sort_func(ldata):
"""
2列目でsortするための関数定義
"""
return ldata[2]
b = sorted(a, key=sort_func)
print(b) # [[2, 3, 1], [3, 8, 3], [1, 2, 5], [-4, 5, 9]]
# 無名関数をkeyにそのまま渡しても良い
# 0列目でsortする例
b = sorted(a, key=lambda x : x[0])
print(b)
提示コードに追加した答え
def LoadCsvFile(csvfile):
"""
引数: 読み込むcsvファイル
戻り値: 点数と名前がならんだ2次元のデータ
"""
o = open(csvfile, "r", encoding='cp932')
lines = o.readlines()[1:]
data = []
for line in lines:
tmp = line.strip().split(',') # 改行コードを削って「,」でsplit()する
data.append([float(tmp[0]), tmp[1]])
return data
def WriteCsvFile(outfile, data):
"""
引数: 保存するcsvファイル
戻り値: 点数と名前がならんだ2次元のデータ
"""
o = open(outfile, "w", encoding="cp932")
o.write("{},{}\n".format("点数", "名前"))
for d in data:
o.write("{},{}\n".format(d[0], d[1]))
print(outfile, "was created.")
def sort_key(x):
return x[0]
def SetDataWrite(smin, smax, data, outfile):
"""
引数: 最小と最大の点数、全データ, 保存するcsvファイル名
戻り値: なし
機能: 点数が最小と最大の範囲にあるデータをdataからスライスしてsort
する。sortしたデータをoutfileにcsv形式で保存する。
"""
sdata = []
for d in data:
if smin <= d[0] and d[0] < smax:
sdata.append(d)
sdata = sorted(sdata, key=sort_key)
WriteCsvFile(outfile, sdata)
data = LoadCsvFile("score.csv")
SetDataWrite(90, 101, data, "秀.csv")
SetDataWrite(80, 90, data, "優.csv")
SetDataWrite(70, 80, data, "良.csv")
SetDataWrite(60, 70, data, "可.csv")
SetDataWrite(0, 60, data, "不可.csv")
別の答え
lines = open("score.csv", encoding="cp932").readlines()[1:]
shu, yu, ryo, ka, fuka = [], [], [], [], []
def sort_key(x):
return x[0]
def output(seiseki, data):
data = sorted(data, key=sort_key)
outfile = seiseki + ".csv"
o = open(outfile, "w", encoding="cp932")
s = "{},{}\n"
o.write(s.format("点数", "名前"))
for d in data:
o.write(s.format(d[0], d[1]))
print(outfile, "was created.")
for l in lines:
d = l.strip().split(',')
d[0], d[1] = float(d[0]), d[1].strip()
score = d[0]
if score < 60:
fuka.append(d)
if 60 <= score and score < 70:
ka.append(d)
if 70 <= score and score < 80:
ryo.append(d)
if 80 <= score and score < 90:
yu.append(d)
if 90 <= score:
shu.append(d)
output("不可", fuka)
output("可", ka)
output("良", ryo)
output("優", yu)
output("秀", shu)
Q5¶
原子がランダムに並んだ水分子のxyzファイル(water_input.xyz)を読んで、結合した水分子(OHHの順)毎にデータを並び替える。
O-H距離が1.2 Ang.以内であれば、結合と判定する。
水分子を出力する順番は、O原子の座標が、原点から近い順番とする。次のよ
うなファイルが生成されれば良いです。
分子毎にO原子の位置が原点に近い順に出力したファイル
water_sort.xyz
ヒント
water_input.xyzを「元素名, x, y, z」の二次元リストで読み込む
原点からの距離を計算する関数(origin_key)をつくる。
sortedにkey=origin_keyを渡して、全原子を原点からの距離でsortする。
OとH、それぞれの原子で二次元リストをつくる。
保存用の空リストを作る(dataset)
一つ一つのOについて、全部のHとの距離を計算しながら、距離が1.2 Ang.以 内なら結合とみなしてdatasetに追加していく。
datasetをwater_sort.xyzに保存する。
答え
後ほど説明するnumpyを使えばもっと簡潔にかつ実行速度の早いプログラムになります。
def OriginDistance(d):
return (d[1]**2 + d[2]**2 + d[3]**2)**0.5
lines = open("water_input.xyz").readlines()[2:]
data = []
for l in lines:
d = l.split()
d[1:4] = [float(s) for s in d[1:4]]
data.append(d)
data = sorted(data, key=OriginDistance)
O, H = [], []
for d in data:
if d[0] == "O":
O.append(d)
if d[0] == "H":
H.append(d)
newdata = []
for o in O:
Hlist = []
for h in H:
dx = o[1] - h[1]
dy = o[2] - h[2]
dz = o[3] - h[3]
r = (dx**2 + dy**2 + dz**2)**0.5
if r < 1.2:
Hlist.append(h)
newdata.append(o)
newdata.append(Hlist[0])
newdata.append(Hlist[1])
o = open("water_sort.xyz", "w")
o.write("{}\n\n".format(len(newdata)))
s = "{:4s}" + 3 * "{:16.10}" + "\n"
for d in newdata:
o.write(s.format(d[0], d[1], d[2], d[3]))
print("water_sort.xyz was created.")
Q6¶
下図に示すような2つの関数に囲まれた黄色の領域の面積を矩形(長方形)の足し合わせで求める。答えは209.96です。
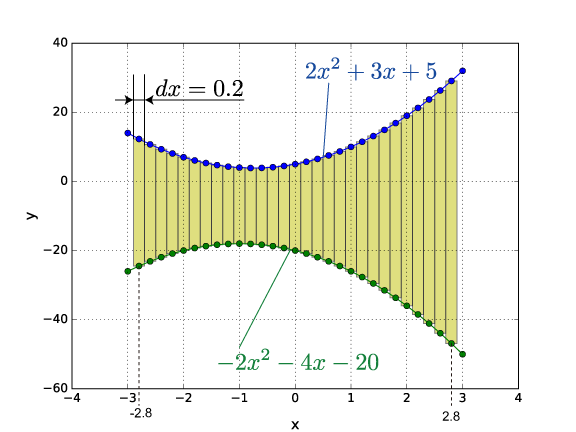
答え
#!/usr/bin/env python
x, y1, y2 = [], [], []
x_width = 3.0 - (-2.8)
dx = 0.2
xn = int(x_width / dx) + 1
x, y1, y2 = [], [], []
for i in range(xn):
xi = -2.8 + i * dx
x.append(xi)
y1.append(2*xi**2 + 3*xi + 5)
y2.append(-2*xi**2 - 4*xi - 20)
area = 0
for i in range(xn):
area += (y1[i] - y2[i])*dx
print("integral: {:.2f}".format(area))